Demystifying DevOps: A Practical Guide for Beginners
This guide is designed to explain the key concepts of DevOps in a way that’s both clear and practical. Each section not only defines a concept or principle but also includes a real-world example to illustrate how it works in practice. These stories are based on actual industry experiences and show how DevOps can solve real problems in real environments.
To help you understand both the theory and the application, each section follows a consistent structure: an explanation of the concept, followed by a relatable, real-world story that illustrates its implementation. This approach helps bridge the gap between abstract ideas and tangible results.
Introduction: Why DevOps Matters
In today’s fast-paced software landscape, delivering high-quality applications quickly and reliably is more important than ever. Yet traditional development and operations teams often struggle with misaligned goals, slow deployment cycles, and fragile infrastructure. Enter DevOps — a movement that bridges the gap between development and operations through culture, collaboration, and automation.
Why should companies care? For business leaders, the key question isn’t just “what is DevOps?” — it’s “why should I hire a DevOps engineer?”
Think of DevOps not as a cost center, but as a profit multiplier. A skilled DevOps engineer reduces downtime, shortens release cycles, automates error-prone tasks, and helps deliver value to customers faster. This improves customer satisfaction, reduces churn, and unlocks new revenue opportunities.
The importance becomes clearer when you examine the consequences of not having these capabilities. A fintech startup faced frequent outages every other week that severely affected user trust. Customer churn increased, and support tickets piled up. After hiring a dedicated DevOps engineer, they transitioned to continuous deployment, improved their observability stack, and introduced automated rollbacks. As a result, outages dropped by 90%, and customer satisfaction scores improved drastically. In just six months, the cost of hiring the DevOps engineer was recovered through retained revenue and new client acquisitions.
What is DevOps?
At its core, DevOps is a cultural and technical approach to software development and IT operations. It promotes:
- Collaboration between traditionally siloed teams (Dev, Ops, QA, Security)
- Automation of manual processes
- Continuous delivery of value to end users
- Resilience and reliability through feedback and learning
DevOps is not a specific tool or job title — it’s a mindset shift. This cultural shift is crucial because without it, tools and processes can’t achieve the transformation alone.
Here’s a look at how this cultural shift plays out in a real-world scenario:
At a large e-commerce company, development and operations teams often blamed each other for system failures, creating a hostile work environment. Releases were stressful and frequently delayed due to last-minute issues. After shifting to a DevOps culture, the organization restructured teams to include both developers and SREs. This fostered joint responsibility, encouraged shared ownership of uptime, and made deployment a collaborative process. As a result, deployment speed increased threefold, and team morale significantly improved. Employee retention rates rose, and more time was spent on innovation than firefighting.
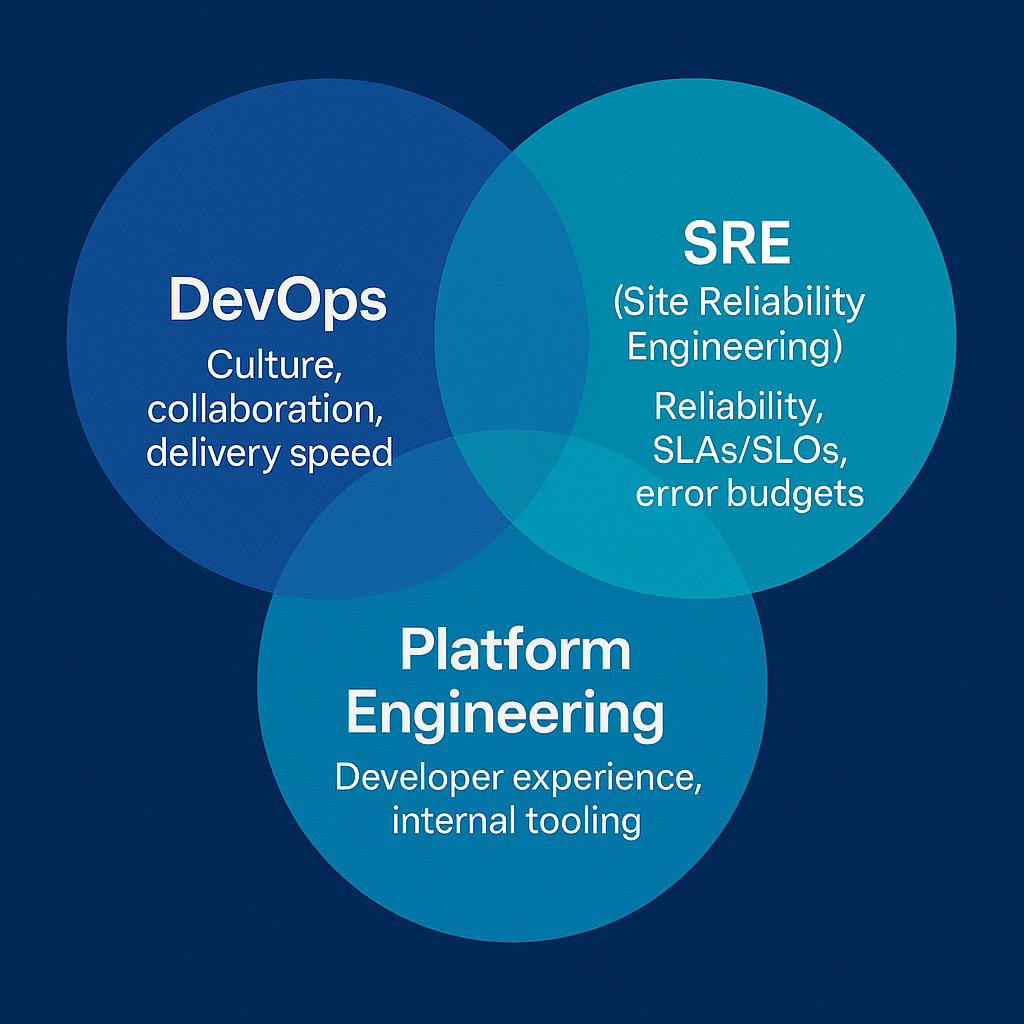
DevOps vs. SRE vs. Platform Engineering
These terms are often used interchangeably, but they serve distinct purposes. To understand where they differ — and where they complement each other — consider the following comparison:
| Role | Focus | Core Objective |
|---|---|---|
| DevOps | Culture, collaboration, delivery speed | Enable faster and safer software releases |
| SRE | Reliability, SLAs/SLOs, error budgets | Balance innovation with uptime & stability |
| Platform Engineering | Developer experience, internal tooling | Build scalable, self-service infrastructure |
Understanding these differences is crucial, especially when building scalable, reliable software systems. While DevOps sets the culture and practices, SRE ensures systems are reliable, and Platform Engineers build the internal tooling to make these practices easy to adopt.
An enterprise SaaS company initially relied on a DevOps engineer to manage CI/CD pipelines and infrastructure provisioning. As the product scaled and the complexity of operations increased, reliability issues became frequent. To address this, they brought in SREs to own service-level objectives and define error budgets. Meanwhile, Platform Engineers developed reusable components, templates, and automation to standardize developer environments. Together, the three disciplines worked in synergy — shipping became predictable, developer velocity improved, and incident rates dropped dramatically.
Core DevOps Principles
- Culture over Tools: Tools help, but trust, communication, and shared goals matter more.
- Automation Everywhere: CI/CD, testing, deployments, and infrastructure should be as code.
- Measure Everything: Metrics, logs, and tracing inform better decisions.
- Fail Fast, Learn Faster: Blameless postmortems and iterative improvements are key.
These principles guide every DevOps practice and decision. Without culture, tools become bandaids. Without automation, speed suffers. Measurement and learning ensure continuous improvement.
Let’s explore these principles through a real-world story:
A mid-sized SaaS provider was plagued by repeated deployment issues due to inconsistent, manual server configurations. Teams were under pressure, and production bugs were frequent. After embracing Infrastructure as Code and building a culture around blameless retrospectives, they identified key process gaps. Over the next quarter, they automated deployments and introduced observability tooling. As a result, they recovered several hours of engineering time each week, and failure analysis led to smarter design decisions — boosting system reliability and internal confidence.
Essential DevOps Practices
- Continuous Integration (CI): Automatically build and test code every time a change is made.
- Continuous Delivery (CD): Ensure code is always in a deployable state.
- Infrastructure as Code (IaC): Manage infrastructure using version-controlled code (e.g., Terraform, Ansible).
- Monitoring and Observability: Use tools like Prometheus, Grafana, or Datadog to detect and fix issues quickly.
- Incident Response: Define on-call rotations, alerting thresholds, and run blameless retrospectives.
Implementing these practices builds the foundation for rapid, reliable software delivery. The challenge lies in prioritizing where to begin.
At a healthtech startup with a growing user base, deployments took three days and were fraught with manual errors. Their first DevOps hire implemented GitHub Actions for CI/CD, Terraform for IaC, and added alerting with Datadog. Deployment time dropped to under ten minutes, with automated rollbacks in case of failure. One critical memory leak was caught early during a live demo, preserving investor confidence and reinforcing the business value of early DevOps investment.
Popular DevOps Toolchains
- CI/CD: Jenkins, GitHub Actions, GitLab CI, CircleCI
- IaC: Terraform, Pulumi, AWS CloudFormation
- Containers & Orchestration: Docker, Kubernetes
- Monitoring: Prometheus, Grafana, ELK Stack, Datadog
- Secrets Management: HashiCorp Vault, AWS Secrets Manager
Selecting the right tools is important, but aligning them with team capability and business goals is even more critical. A tool used poorly can do more harm than good.
A large enterprise team adopted Kubernetes because it was seen as the industry standard. However, they lacked in-house expertise and proper planning. Cluster sprawl and frequent configuration issues consumed engineering bandwidth. A seasoned DevOps engineer streamlined the toolchain, replacing manual workflows with GitOps using ArgoCD. By aligning tooling with the team’s skill level and business goals, maintenance effort was halved and release confidence improved.
Getting Started With DevOps
- Start Small: Automate one part of your workflow — like deployments or tests.
- Build a Feedback Loop: Use monitoring and alerts to understand your system.
- Break the Silos: Create cross-functional teams where devs and ops work together.
- Learn Continuously: DevOps is about experimentation, failure, and iteration.
Even small changes can have outsized impacts over time.
A bootstrapped product team started with no DevOps practices in place. One team member introduced GitHub Actions for testing and Terraform for environment provisioning. Gradually, they built version-controlled infrastructure and automated daily deployments. Over time, users began noticing faster bug fixes and better uptime. The support team saw a drop in tickets, and developers could focus on new features rather than firefighting.
DevOps in Different Environments
DevOps isn’t one-size-fits-all. The strategies and tools you use must adapt to your organization’s size, maturity, and business goals. Here’s how DevOps manifests across different environments:
Startups
- Focus: Speed, iteration, and rapid feedback.
- Challenges: Limited resources, lack of formal processes, and evolving requirements.
- Typical Stack: GitHub Actions, Docker, Terraform, Heroku/AWS, lightweight monitoring like UptimeRobot.
- Advice: Automate early, use managed services where possible, and optimize for simplicity.
Example: A two-person SaaS team used GitHub Actions and Terraform to deploy to AWS. With minimal setup, they automated daily deployments, ran tests on every push, and added Slack alerts for failed jobs — dramatically increasing stability and confidence without slowing down development.
Enterprises
- Focus: Stability, compliance, scalability, and governance.
- Challenges: Legacy systems, siloed teams, and resistance to change.
- Typical Stack: Jenkins, Kubernetes, ServiceNow, Ansible, Splunk, HashiCorp Vault.
- Advice: Start with cultural change, unify tooling across teams, and incrementally modernize infrastructure.
Example: A Fortune 500 company transitioning to DevOps started by breaking down monoliths into microservices and introduced a centralized CI/CD platform. They launched pilot programs within motivated teams, which created internal success stories and eventually led to broader organizational adoption.
Remote/Distributed Teams
- Focus: Async collaboration, observability, and documentation.
- Challenges: Communication gaps, coordination complexity, lack of shared physical infrastructure.
- Typical Stack: GitLab CI, Terraform Cloud, ArgoCD, PagerDuty, Notion/Confluence.
- Advice: Emphasize transparency, codify everything (infra, runbooks, alerts), and foster strong written communication.
Example: A fully remote tech consultancy implemented GitOps practices using ArgoCD and Terraform Cloud. All deployments were traceable via pull requests, and incident playbooks lived in Confluence. This ensured everyone stayed aligned, regardless of time zone.
Final Thoughts
DevOps isn’t a silver bullet. It’s a long-term investment in people, processes, and tools. By focusing on collaboration, automation, and continuous improvement, you’ll build more resilient systems — and happier teams.
For business leaders: A DevOps engineer isn’t a cost — it’s an asset. With the right practices, a single engineer can:
- Eliminate downtime that costs you users and money
- Accelerate time-to-market for revenue-generating features
- Reduce technical debt that drains productivity
DevOps is how tech companies compete at scale. It turns infrastructure into a growth engine.
Whether you’re a developer, sysadmin, or manager, embracing DevOps principles will help you deliver better software, faster.
Coming Next: A deeper dive into real-world DevOps workflows, from IaC to incident response. Follow to stay updated.
#DevOps #SRE #PlatformEngineering #CICD #30DaysOfDevOps